


معماریهای مختلف پایگاه داده ها
Database Architectures
در این گزارش قصد داریم معماری های مختلف پایگاه داده را مورد بررسی قرار دهیم.
معماری پایگاه داده ها به چند دسته مختلف تقسیم می شوند:
· سیستم های متمرکز[1]
· سیستم های مشتری/خدمتگزار [2]
· سیستم های موازی [3]
· سیستم های توزیع شده [4]
در ادامه به شرح سیستم های مختلف می پردازیم.
1. سیستمهای متمرکز [Silb]
در این نوع سیستم ها تمامی اطلاعات در یک پایگاه ذخیره و همچنین بازیابی می شوند بدین ترتیب که کاربران برای استفاده از اطلاعات ذخیره شده فقط باید به دستگاهی که پایگاه در آن ذخیره شده است مراجعه کنند. اینگونه پایگاه داده ها که امروزه کمتر مورد استفاده قرار می گیرند، برای استفاده در مواردی که کاربرد زیادی دارند ایجاد می شوند.
همانطور که در شکل مشاهده می شود، در این نوع معماری پایگاه داده در یک کامپیوترقرار دارد. بدین معنی که در این معماری یک یا بیشتر پردازنده و یک حافظه مشترک بین پایگاه داده و سیستم عمل وجود دارد.
از مزایای این نوع معماری می توان موارد ریز را برشمرد:
· سادگی در طراحی
· سادگی در استفاده
· عدم نیاز به امکانات سخت افزاری یا نرم افزاری خاص
همچنین از معایب آن می توان به موارد زیر اشاره کرد:
· تک کاربره بودن
· مشکل بودن استفاده در سازمانهای بزرگ
با توجه به گسترش روز افزون استفاده از پایگاه داده ها و همچنین بیشتر شدن حجم اطلاعات و تعداد کاربران سیستم های متمرکز به تدریج جای خود را به معماری هایی با قابلیت های بیشتر برای استفاده گسترده تر دادند.
2. سیستم های مشتری/خدمتگزار [Silb]
این نوع معماری بعد از معماری متمرکز و به علت نا کارآمدی معماری متمرکز در سیتم های بزرگتر بوجود آمد. در این نوع معماری قسمت های مختلف پایگاه داده در کامپیوتر های مختلف قرار می گیرند. در این روش یک کامپیوتر نقش سرور را به عهده می گیرند و کاربران می توانند با استفاده از کامپیوتر های دیگر و متصل شدن به سرور از پایگاه داده استفاده کنند. همانطور که مشخص است کاربران و کامپیوترها برای اتصال به سرور نیازمند به شبکه کامپیوتری هستند پس در واقع شبکه های کامپیوتری یکی از ملزومات این نوع معماری به حساب می آید.
بخش های مختلف پایگاه داده ها در این نوع معماری بر حسب کاربری به دو بخش تقسیم می شود:
· Back-end : این قسمت وظیفه بررسی و کنترل دسترسی ها، بررسی و بهینه سازی پرس و جو[5] ها و کنترل همزمانی ها و سالم بودن پایگاه داده ها را به عهده دارد.
· Front-end: شامل ابزار هایی برای نمایش و زیباسازی نتایج پرس و جو ها مثل ابزارهای تولید فرم ها و ابزار های گزارش گیری می باشد.
برای ایجاد ارتباط درست میان دو قسمت فوق نیازمند یک لایه و بستر است. این بستر میتواند از دو طریق دستورات SQL و یا API ها برقرار شود.
در مقایسه این نوع معماری با معماری متمرکز با استفاده از Mainframe ها می توان به مزایای زیر اشاره کرد:
· افزایش میزان کاربری سیستم با توجه به هزینه
· راحت تر شدن گسترش دادن و توزیع کردن منابع
· تولید واسط های کاربر بهتر
· راحت تر شدن نگهداری سیستم
در این نوع معماری، سرورها از لحاظ عملکردی به دو بخش مجزا تقسیم می شود:
· سرورهای داده ای: این نوع سرور ها بیشتر در سیستم های شی گرا مورد استفاده قرار می گیرند
· سرور های تراکنشی: این نوع سرور ها بیشتر در سیستم های رابطه ای مورد استفاده قرار می گیرند
در ادامه به شرح این دو بخش می پردازیم.
در سرورهای تراکنشی که به آنها سرورهای پرس و جو هم گفته می شود روش کار بدین صورت است که درخواست های کاریران به این سیستم ها ارسال می شود و نتیجه در این سرور ها تولید و به کاربر ارسال می شود. درخواست های کاربران به صورت دستورات RPC و دستورات SQL ارسال می شود.برای ارسال و دریافت نیاز به نرم افزار هایی هست مانند ODBC و JDBC که وظیفه ارتباط با سرور و ارسال پرس و جوها و دریافت نتایج را به عهده دارد.
برای پیاده سازی سرورهای تراکنشی از تعدادی پردازه که حافظه مشترک دارند استفاده می شود که معمولا برای بهبود پردازه ها هر کدام از آنها Multithread مورد استفاده قرار می گیرند.
تعدادی از پردازه هایی که حتما یک سرور تراکنشی باید داشته باشد در زیر می بینیم:
· پردازه های سرور: این پردازه ها وظیفه دریافت پرس و جو ها و تولید پاسخ ها را به عهده دارد
· پردازه مدیریت همزمانی: وظیفه مدیریت همزمانی درخواست ها را عهده دار است این امکان یا با استفاده از سمافورهای سیستم عامل و یا با استفاده از روش های مثل Test and Set فراهم آورده می شود.
· پردازه نگارنده پایگاه داده: که وظیفه نوشتن نتایج پرس و جو ها را بر روی دیسک به عهده دارد
· پردازه نوشتن logها: این پردازه اطلاعات نوشته شده روی بافر برای ذخیره به حافظه های پایدار می نویسد.
· پردازه check point: این پردازه مسؤلیت چک کردن پردازشها در مراحل مشخص انجام می دهد
· پردازه Monitor Process: وظیفه این پردازه کنترل عملکرد دیگر پردازه ها و در صورت لزوم Recover کردن آن پردازه می باشد.
برای مشخص تر شدن چگونگی طرز کار و ارتباط بین پردازه ها شکل زیر ارایه می شود.
نوع دیگر سرور ها سرور های دیتا هستند که بیشتر در سیستم های شی گرا استفاده می شود. این سرورها معمولا در شبکه های Lan مورد استفاده قرار می گیرد.
روش کار به این صورت است که داده ها به Client ها برای پردازش منتقل می شود و داده های پردازش شده به سرور برای ذخیره سازی برگردانده می شوند. این سیستم ها بیشتر برای معماری شی گرا استفاده می شوند.
3. معماری موازی [RAMA]
معماری موازی به نوعی از معماری گفتع می شود که در این نوع معماری سعی شده است که با پیاده سازی روش های کار موازی کارایی سیستم را افزایش دهیم. پردازش های موازی می تواند در بخش های مختلف و وظایف مختلف از قبیل خواندن داده ها، تولید فهرست ها و پردازش پرس و جو ها پیاده سازی شود. همچنین در این نوع سیستم ها داده ها می توانند از لحاظ قرار گیری فیزیکی در قسمت های مختلف قرار گرفته باشند.
ایده اصلی در معماری موازی استفاده از پردازش های موازی در مراحل مختلف تا آنجا که امکان دارد برای بهبود کارایی سیستم است.
چهار نوع معماری مختلف برای این سیستم ها وجود دارد. معماری نوع اول معماری بر پایه حافظه مشترک است در این معماری چند پردازنده که از طریق یک یک شبکه پرسرعت به هم متصل هستند داده های مورد استفاده خود را در یک حافظه مشترک بین هم قرار می دهند.
نوع دیگر این معماری، معماری بر پایه دیسک سخت مشترک است. دز این روش چند پردازنده با حافظه های مخصوص خود متصل شده به هم توسط شبکه پرسرعت و با یک دیسک سخت مشترک با هم در ارتباطند.
نوع سوم معماری، معماری بدون عنصر مشترک بین پردازنده هاست. هر پردازنده در این روش حافظه و دیسک سخت خود را دارند و هیچ حافظه ای را به اشتراک نمی گذارند. تمامی ارتباطات میان پردازنده ها از طریق شبکه بین آنها ایجاد می شود.
نوع چهارم استفاده از معماری چمد سطی است که درواقع ترکیبی از حالت های فوق است که بخش بخش به هم از طریق روش بدون اشتراک گذاشتن منابع به هم متصل شده اند ولی درون هر بخش پردازنده ها با هم منابع را به اشتراک می گذارند.
دو روش به اشتراک گذاشتن حافظه و دیسک سخت دارای مشکلی هستند که با افزایش تعداد کاربران مشخص می شود. در این دو روش با بالارفتن تعداد پردازنده ها استفاده از فضای مشترک هم بیشتر می شود، از آنجایی که داده های منتقل شده در شبکه زیادتر می شود سرعت و در نتیجه کارایی کل هم کاهش پیدا می کند.
شکل زیر چگونگی ارتباط بین افزایش تعداد پردازنده ها و تاثیر آن بر سرعت در این دو نوع روش قابل بررسی است.
مشکل ایجاد شده امروزه مورد تحقیق و بررسی بسیاری از علاقمندان قرار دارد و گروه های متعدد روش هایی را برای چگونگی حل این مشکل ارایه داده و می دهند. برای نمومه یکی از روش ها استفاده از مفاهیم “شبکه های عصبی” در حل این مشکل است. [iii]
3.1 اجرای پرس و جو ها در معماری موازی
برای اجرا پرس و جو ها ابتدا باید درخواست پرس و جو ها به درختواره عملیاتی تبدیل شود. در این درختواره می توان با حرکت از پایین به بالا دستوراتی که ورودی های آنها مشخص شده است را به صورت موازی اجرا کنیم. در این روش دستوراتی در درختواره وجود خواهند داشت که هنوز ورودی آنها مشخص نشده است در نتیجه این دستورات تا آماده شدن ورودی های آن اجرا نخواهد شد.
از طرفی از روش پردازش موازی می توان در مرحله دیگر یعنی آماده شدن اطلاعات و اجرای آنها می توان ورودی ها را بخش بندی کرد و با آماده شدن هر بخش عملیات آن اجرا شود و در واقع از روش Pipelining استفاده کرد.
در بخش بندی داده ها روش هایی مانند Round- robin, استفاده از روش Hash و همینطور روش Range partitioning استفاده کرد. روش RR بیشتر برای مواردی که کل داده ها مورد پردازش قرار می گیرند بیشتر استفاده می شود. دو روش دیگر برای مواقعی که تنها بخش های خاصی از داده ها مورد پردازش قرار می گیرند استفاده می شوند.
3.2 عملگرهای تک عملوندی در معماری موازی
در این بخش به چگونگی اجرای عملگرهای تک عملوندی در معماری موازی بدون به اشتراک گذاشتن منابع را مورد بررسی قرار می دهیم.
مرتب سازی:
برای مرتب سازی روش اول بدین گونه است که هر پردازنده داده هایی که در دیسک سخت مریوط به خود را مرتب کنند و در نهایت نتایج را با هم ادغام کنیم.
اما روش کاملتر اینست که در ابتدا داده ها را با توجه به توان هر پردازنده بین پردازنده ها توزیع عادلانه کنیم و در نهایت نتایج را با هم ادغام کنیم. مزیت این روش نسبت به روش اول توزیع درست داده ها و استفاده درست و عادلانه از پردازنده هاست.
-عمل Join
برای عمل Join بین دو رابطه هم از همان روش فوق یعنی تقسیم داده ها و توزیع آنها بین پردازنده ها استفاده می شود. در این روش دو نوع بخش بندی محتمل است. روش اول تقسیم بندی بدون توجه به عامل Join است که در این حالت تمامی داده ها بدون هیچ پیش فرضی تقسیم می شوند. روش دوم استفاده از عامل ارتباط است که در این حالت داده ها را با توجه به عامل ارتباط و با توجه به تعداد پردازنده ها تقسیم می کنیم. پس از تقسیم بین پردازنده ها عمل Join در هرکدام انجام می شود و نتیجه نهایی از اجتماع این نتایج بدست می آید. در هر کدام از پردازنده ها برای عمل Join از روش Hash Join که قبلا توضیح داده شده است استفاده می شود.
یک روش برای بهبود عمل Hash Join اینست که داده ها را به بخش های متعدد تقسیم کنیم و عمل Join هر بخش را به صورت موازی اجرا کنیم . شکل زیر چگونگی این روش را نشان می دهد.
عملگرهای دیگر نظیر عملگرهای گروهی مانند Sum نیز امروزه بحث های مهمی را در این زمینه ایجاد کرده اند و گروه های مختلفی بر روی چگونگی اعمال این عملگرها کار می کنند. یکی از روش های اعمال پردازش موازی اعمال روش بخش بندی و توزیع داده ها مانند روش های فوق است که برای عملگرهای گروهی نیاز به تغییرات و طراحی روش جدید است[iv].
4. معماری پایگاه داده توزیع شده [RAMA]
در این معماری، داده ها در محلهای مختلفی نگهداری می شود. دو خاصیت مهم این نوع از پایگاه داده ها :
1. استقلال داده های توزیع شده[6]: کاربران باید بتوانند بدون اطلاع از محل ذخیره داده ها، از پایگاه داده ها پرس و جو کنند.
2. عدم تفاوت تراکنشهای توزیع شده[7]: کاربران باید بتوانند دقیقاً مشابه روشی که در مورد تراکنشهای محلی(local) عمل می کردند، تراکنشهایی بنویسند که به داده ها در محلهای مختلف دسترسی داشته باشد و آنها را بروز کند.
اگرچه این دو خاصیت مطلوب هستند ولی در عمل در بعضی موارد عملی کردن آنها مهم نیست و حتی وقتی که داده ها در سراسر جهان توزیع شده اند این دو خاصیت مطلوب هم نیستند.
انواع پایگاه داده های توزیع شده:
اگر داده ها توزیع شده باشند و تمام DBMSها از یک نوع بودند، یک سیستم پایگاه داده های توزیع شده همگن داریم. اگر داده ها در محلهای مختلف باشند ولی نوع DBMSها مختلف باشند در این حالت یک سیستم پایگاه داده های توزیع شده ناهمگن داریم. کلید ایجاد سیستم های ناهمگن داشتن استانداردهای مقبول برای پروتکلهای گذرگاهها می باشد.
معماریهای مختلف برای سیستم مدیریت پایگاه داده های توزیع شده:
1. سیستمهای مشتری/خدمتگزار: در این معماری وظایف مشتری و خدمتگزار کاملاً از هم جداست و در هر لحظه یک یا چند پردازه مشتری و یک یا چند پردازه خدمتگزار در سیستم موجود است و پردازه های مشتری می توانند به هر یک از پردازه های خدمتگزار پرس و جو بفرستند. این معماری به دلیل سادگی نسبی پیاده سازی و متمرکز بودن خدمتگزار خیلی رایج است. در این سیستم کاربر می تواند با استفاده از واسط کاربر گرافیکی در سیستم مشتری کار کند و نیازی به کار کردن با واسطهای کاربر نامأنوس در سیستم خدمتگزار نیست.
2. سیستم تشریک مساعی خدمتگزار [8]: سیستممشتری/خدمتگزار به یک پرس و جو اجازه پوشش چند خدمتگزار را نمی دهد زیرا در این صورت مشتری باید پرس و جو را به بخشهای مختلف تقسیم کرده تا در خدمتگزارهای مختلف اجرا شوند و جوابها را با هم ترکیب کند که این کار اصل جدا بودن وظایف مشتری از خدمتگزار را زیر سوال می برد. در سیستم تشریک مساعی مجموعه ای از خدمتگزارها داریم که هر کدام توانایی اجرای تراکنش روی داده های محلی را دارند و با همکاری یکدیگر تراکنشهایی که شامل چند خدمتگزار می شود را اجرا می کنند.
3. سیستمهای میان افزار [9]: محیطی را در نظر بگیرید که در آن تمام خدمتگزاران قابلیت پشتیبانی از پرس و جوهایی که از چند خدمتگزار استفاده می کنند را ندارند، سیستمهای میان افزار برای این محیط از پایگاه داده های توزیع شده طراحی شده است. ایده اصلی در این روش وجود فقط یک خدمتگزار با قابلیت مدیریت تراکنشهای توزیع شده است و سایر خدمتگزاران فقط پرس و جوهای محلی را پاسخ می هند. می توان این خدمتگزار خاص را یک لایه نرم افزاری در نظر گرفت که به آن میان افزار می گویند.این نرم افزار داده ای درا نگهداری نمی کند.
تکرار [10]
تکرار به این معنی است که ما کپی های متعددی از یک رابطه و یا یک قطعه از یک رابطه را ذخیره کنیم. به طور مثال اگر R1 و R2 و R3 ،قطعه های رابطه R باشند، ما ممکن است یک کپی از R1 داشته باشیم ولی مثلاً R2 در دو سایت موجود است و R3 در تمامی سایت ها.
مزایای این روش عبارتند از :
1- افزایش دسترس پذیری داده : اگر یک سایت که شامل یک کپی از یک رابطه است خراب شود ما همان داده را می توانیم در سایت دیگری پیدا کنیم همچنین اگر یک کپی محلی از رابطه هایی که در سایت های دیگر هستند را داشته باشیم کمتر در معرض تهدید از بین رفتن کانال ارتباطی خواهیم بود. Replication دارای دو نوع مختلف همگام و غیر همگام می باشد، تفاوت این دو نوع در روش به روز رسانی کپی های یک رابطه است در زمانی که یک رابطه تغییر می کند.
2- پرس و جو ها با سرعت بیشتری قابل اجرا هستند زیرا یک کپی محلی از داده های ذخیره شده درپایگاه داده موجود است.
3- انجام وظایف بصورت موازی: در موردي كه بيشتر دسترسي هاي به رابطه r براي خواندن از رابطه r مي باشد، چندين سايت مي توانند پرس و جو را به صورت موازي پردازش كنند، نسخه هاي بيشترr شانس اينكه داده مورد نياز در سايتي كه تراكنش در حال اجراست، يافته شود را بالا مي برد از اين رو تکرار داده انتقال داده بين سايتها را حداقل مي كند.
4- افزایش سربار بروز کردن: سيستم بايستي مطمئن شود كه تمام نسخه هاي رابطه r سازگار هستند. بنابراين هرگاه r، بروز شود اين بروز رسانی بايستي در تمامي سايتهايي كه حاوي نسخه ها هستند منتشر شود. در نتيجه overhead زياد مي شود.
اگر رابطه r ، نسخه برداري شده باشد، يك كپي از رابطه r در دو يا بيش از دو سايت ذخيره مي شود. در بيشتر موارد، با تکرار داده کامل روبرو هستیم، به اين منظور كه هر نسخه بر روي تمامي سايتها ذخيره مي شود. كنترل update هاي همزمان توسط چندين تراكنش روي داده هاي نسخه برداري شده مشكلتر از سيستمهاي متمركز است. ما مي توانيم مديريت نسخه هاي رابطه r را با انتخاب يكي از آنها به عنوان كپي اصلي r ساده كنيم.
شفافیت Transparency :
كاربر يك پايگاه داده توزيعي نبايد نياز به دانستن اين داشته باشد كه داده ها به صورت فيزيكي در كجا واقع شده اند يا اينكه در يك سايت محلي خاص داده ها چگونه دستيابي مي شوند. به اين خاصيت data transparency گفته مي شود و مي تواند چند فرم داشته باشد:
· Fragmentation Transparency: كاربر نيازي به دانستن اينكه يك رابطه چگونه بخش بندي شده است ندارد.
· Replication Transparency: كاربر هر شي داده را منطقا يكتا مي بيند. سيستم توزيعي ممكن است يك شي را تکرار كند تا کارایی يا در دسترس بودن داده ها را افزايش دهد. كاربر نگران اين موضوع نيست كه كدام اشياء داده اي تکرار شده اند يا در كجا اين نسخه ها قرارگرفته اند.
· Location Transparency: كاربران نياز به دانستن مكان فيزيكي داده ها ندارند. پايگاه داده توزيعي بايستي قادر به يافتن هر داده اي توسط اعمال شناسه داده در تراكنش كاربر باشد.
Data item ها مثل رابطه ها، بخشها، و نسخه ها بايستي نامهاي يكتا داشته باشند. اعمال اين خاصيت در پايگاه داده هاي متمركز آسان است. در يك پايگاه داده توزيعي ما بايد مراقب باشيم كه دو سايت از يك نام مشابه براي data item هاي مجزا استفاده نكنند. يك راه براي اين مشكل اين است كه تمامي نامها در يك name server مركزي ذخيره شوند. name server كمك مي كند تا مطمئن شويم كه يك نام مشابه براي data item هاي مختلف استفاده نمي شود. ما همچنين مي توانيم از name server براي پيداكردن يك data item، طبق نام Item استفاده كنيم.
اين راه حل دو مشكل بزرگ دارد:
1- name server مي تواند گلوگاه كارايي سيستم ما شود اگر محل data item طبق نامهايشان پيدا شود.
2- اگر name server،مشکلی پیدا کند سيستم از كار مي افتد.
رویکردهاي ديگر كه بيشتر استفاده مي شوند اين است كه هر سايت به هر نام كه توليد مي كند id خودش را به صورت پيشوند اضافه كند. از اين جهت هيج كنترل مركزي نياز نيست .اما اين روش location transparency را نقض مي كند .(برخي پایگاه داده ها آدرس اينترنتي خود را به عنوان id سايت استفاده مي كنند.)
براي غلبه بر اين مشكل سيستم پايگاه داده مي تواند مجموعه از نامهاي مستعار[11] براي data item ها ايجاد كند.كاربر مي تواند به data item توسط نامهاي ساده كه توسط سيستم به نامهاي كامل ترجمه مي شوند مراجعه كند. نگاشت[12] نامهاي مستعار به نامهاي واقعي مي تواند در هر سايت ذخيره شود.با نامهاي مستعار كاربر مي تواند از محل فيزيكي data item،ناآگاه بماند . همچنين چنانچه مدیر پایگاه داده ها تصميم به انتقال data item از سايتي به سايت ديگر رفت كاربر دچار مشكل نشود.
مدیریت کاتالوگ توزیع شده[13]:
نام گذاری اشیاء[14] :
در صورتی که یک رابطه قطعه بندی و تکرار می شود ما باید قادر باشیم هر کپی از یک قطعه را به صورت یکتا مشخص کنیم. یک راه حل اینست که یک global unique ID توسط یک name server تولید شود.
مشکلی که این راه حل دارد اینست که اشیاء محل باید بتوانند بدون در نظر گرفتن اسامی سراسری نام گذاری شوند. راه حلی کلی اینست که هر نام چندین فیلد داشته باشد. یک فیلد نام محلی که هر سایت مسئول نام گذاری آن است و یک فیلد Birth Site که سایتی که رابطه را تولید کرده و اطلاعات تمامی Fragment ها و کپی های رابطه را دارد، را مشخص می کند.
توسط این دو فیلد یک رابطه به صورت یکتا نام گذاری می شود که ما به آن global relation name می گوئیم. برای مشخص کردن یک replica ما از ترکیب global relation name و replica ID استفاده می کنیم و به آن global replica name می گوئیم.
ساختار کاتالوگ[15]:
کاتالوگ می تواند بر روی یک سایت مرکزی باشد ولی درصورتی که آن سایت خراب شود کاتالوگ سیستم از بین می رود روش دیگر اینست که در هر سایت یک کپی از کاتالوگ سیستم نگهداری شود. ولی اشکال این روش هم اینست که هر تغییر در کاتالوگ سیستم باید به تمامی سایت های دیگر broadcast شود.
روش دیگر اینست که در هر سایت یک کاتالوگ محلی که شامل اطلاعات کپی داده ها در آن سایت می باشد، موجود باشد همچنین کاتالوگ در سایت مادر (birth site) مسئول اینست که محل تکرار های آن رابطه را ذخیره کند هنگامی که یک نسخه جدید تولید می شود و یا یک نسخه از یک سایت به سایت دیگری منتقل می شود اطلاعات سایت مادر باید به روز رسانده شود. هنگامی که یک رابطه تولید می شود اطلاعات کاتالوگ سایت مادر بررسی می شود.
استقلال داده توزیع شده[16]:
استقلال داده توزیع شده به این معناست کاربران بدون اینکه اطلاعی از تکرار ها و قطعه های یک رابطه باشند قادر به نوشتن پرس و جو های خود باشند. بازسازی رابطه ها وظیفه DBMS می باشد. به عبارت دیگر کاربران هنگام اجرای یک پرس و جو نباید نام کامل اشیاء داده ای را مشخص کنند.
در کاتالوگ سیستم نام محلی هر رابطه ترکیبی از نام کاربر و نام تعریف شده توسط کاربر برای آن رابطه است. هنگامی که کاربر query خود نام یک رابطه را می آورد، DBMS نام کاربر را به این نام اضافه می کند تا نام محلی رابطه را بدست آورد و سپس site-id کاربر را به آن اضافه می کند تا global relation name را بسازد. با جستجو براساس global name درون سایت مادر DBMS می تواند محل تکرار های آن رابطه را پیدا کند.
تراکنش های توزیع شده[17] :
هنگامی که یک تراکنش در یک سایت ثبت می شود، مدیر تراکنش ها در آن سایت، آن تراکنش را به چند زیر تراکنش تقسیم می کند به طوری که هر زیر تراکنش در سایت خاصی اجرا می شود.
بازیابی توزیع شده[18]:
مقوله بازیابی در معماری های توزیع شده پیچیده تر از معماری های متمرکز است زیرا :
1- 2 نوع Failure می توانیم داشته باشیم یکی از Failure کانال های ارتباطی و Failure سایت های دیگری که زیر تراکنش ها در آنها در حال اجرا می باشند.
2- یا تراکنش تمامی سایتها باید Commit شود و یا هیچ کدام از آنهاکه این مسئله توسط Commit Protocol تضمین می شود.
پروتوکلهای اجرای معمولی و ثبت[19] :
در حین اجرا اعمال زیر تراکنش ها در آن سایت ثبت می شود. و نهایتاً Commit protocol بررسی می کند که آیا تمامی زیر تراکنش های آن تراکنش Commit شده اند یا خیر.
به مدیر تراکنش های سایتی که تراکنش به آن تعلق داد Coordinator می گویند و به مدیر تراکنش های سایتهایی که در آنها زیر تراکنش ها اجرا می شوند Subordinator می گویند هنگامی که کاربر تصمیم می گیرد که تراکنش را Commit بکند دستور Commit به Coordinator تراکنش فرستاده می شود و پروتکل two phase commit به صورت زیر اجرا می شود.
1- Coordinator یک پیغام Prepare به تمامی Subordinate ها می فرستد.
2- هنگامی که Subordinate پیغام prepare را دریافت می کند تصمیم می گیرد که آیا تراکنش را abort کند و یا commit کند. سپس در prepare log خود وضعیت را ثبت می کند و یک پیغام بله و یا خیر به Coordinator می فرستد.
3- اگر Coordinator از تمامی Subordinate ها پیغام بله را دریافت کند یک Commit را در فایل log ثبت می کند و پیغام Commit را به تمامی Subordinate ها می فرستد. ولی در صورتی که حتی از یک Subordinate پیغام خیر دریافت کند و یا اینکه اصلاً پیغامی دریافت نکند پیغام abort را به تمامی Subordinate ها می فرستد. و آن را نیز log می کند.
4- هنگامی که یک Subordinate پیغام abort را دریافت می کند abort را در فایل log ثبت می کند و یک پیغام ack به coordinator می فرستد و زیر تراکنش خود را abort می کند. در صورتی که Subordinator پیغام commit دریافت کند نیز آن را log می کند و یک ack به coordinator می فرستد و زیر تراکنش را commit می کند.
5- هنگامی که coordinator از تمامی Subordinator ها پیغام ack را دریافت می کند برای تراکنش end را در فایل log ثبت می کند.
دلیل اینکه به این پروتکل two phase commit می گویند اینست که دو دسته پیغام رد و بدل می شود یک دسته پیغام های نظرسنجی [20] و دسته دوم پیغام های termination.
شروع دوباره بعد از Failure :
هنگامی که یک سایت پس از یک crash دوباره احیا می شود، فرآیند Recovery را فراخوانی می کند. فرآیند recovery و فایل log را می خواند و تمامی تراکنش هایی که هنگام Failure درحال اجرای commit protocol بودند را پردازش می کند.
· اگر برای تراکنش T مایک رکود Commit داریم T را Redo می کنیم و اگر رکورد abort باشد آن را undo می کنیم. در صورتی که این سایت coordinator باشد و از روی رکوردهای log می توان فهمید باید به تمامی Subordinate ها پیغام Commit و یا abort بفرستیم و بقیه کادر همانند قبل ادامه دهیم.
· اگر مایک رکورد Log برای تراکنش T داریم ولی رکورد Commit و abort نداریم آنگاه متوجه می شدیم که این سایت Subordinate است، از رکورد coordinator را شناسائی می کنیم و با آن ارتباط برقرار می کنیم تا وضعیت تراکنش T را بیابیم. هنگامی که coordinator وضعیت تراکنش را پاسخ داد (commit abort) همانند مورد قبل عمل می کنیم.
· اگر هیچ گونه log برای تراکنش T نداشته باشیم، مسلماً T برای commit نظر خواهی نکرده است در نتیجه ما می توانیم T را به سادگی abort کنیم. در این حالت ما نمی توانیم مشخص کنیم که سایت Coordinator بوده است یا Subordinate.
اگر سایت Coordinator ، fail شود، Subordinate ها نمی توانند تصمیم بگیرند که آیا زیر تراکش را Commit یا abort بکنند، در این موقعیت T بلاک شده است.
البته subordinate ها در این مرحله می توانند با یکدیگر ارتباط برقرار کنند تا از وضعیت یکدیگر مطلع بشوند و در صورتی که یکی از آنها abort کرده است بقیه نیز abort کنند.
References:
i.Database System Concepts (4th edition)-2001-Abraham Silberschatz, Henry F. Korth, S. Sudarshan
ii.Database Management Systems – 2000 – R. Ramakrishnan, J. Gehrke
iii. Jose´ Castro, Michael Georgiopoulos, Ronald Demara, Avelino Gonzalez - "Data-partitioning using the Hilbert space filling curves: Effect on the speed
of convergence of Fuzzy ARTMAP for large database problems"
iv. Damianos Chatziantonioua, Kenneth A. Rossb - "Partitioned optimization of complex queries"
[1] Centralized Database
[2] Client Server Database
[3] Parallel Database
[4] Distributed Database
[5] Query
[6] Distributed Data Independence
[7] Distributed Transaction Atomicity
[8] Collaboration Server System
[9] Middleware
[10] Replication
[11] Alias
[12] Mapping
[13] Distributed Catalog Management
[14] Objects Naming
[15] Catalog Structure
[16] Distributed Data Independence
[17] Distributed Transactions
[18] Distributed Recovery
[19] Normal Execution and Commit Protocols
[20] Voting phase
--------------------------------------------------------------------------------------------
در ادامه مقاله ای با همین عنوان به همراه عکس و نمودار آماده دانلود رایگان می باشد.
برچسب های مهم

دانلود فایلهای بسته آمادهچاپ و نصب تابلو اعلانات مسجدنما همیشه دنبال این بودی یه جایی باشه تا راحت بتونی محتوای مطمئن با طراحی خوب را پیدا کنی؟ همیشه دنبال این بودی یکی کارهای محتوایی را ناظر به مسائل روز انجام بده و دغدغه تأمین محتوا را نداشته باشی؟ همیشه ... ...
عنوان پاورپوینت: پاورپوینت سوره یس، سوره صافات و تفسیر نمونه درس 10 قرآن پایه هشتمفرمت: پاورپوینت قابل ویرایش تعداد اسلاید: 26 پوشش کامل درس (جلسه اول و دوم) به همراه صوت آیات پاورپوینت قابل ویرایش با محیط حرفه ای منطبق با آخرین ... ...

حرکت تاریخی کرد به خراسان.pdf ... ...


گوش کردن به سابلیمینال به معنای گوش دادن به پیامها یا اطلاعاتی است که به صورت ناخودآگاه به فرد منتقل میشوند. این پیامها معمولاً به طور زیرآگاهی تأثیر میگذارند و به طور مستقیم در سطح آگاهی فرد قرار نمیگیرند. پخش زیرآگاه پیامها این میتواند از طریق موسیقی، متنهای ... ...

پژوهی در پیدایش و تحولات تصوف و عرفان.pdf ... ...





ما نمیمیریم.pdf گفتگوهای عجیب جرج اندرسون با دنیای ماورا و زندگی پس از مرگ ... ...

تاریخ مصور جهان دنیای باستان.pdf انسان های عصر حجر،مصر باستان،یونان باستان و امپراطوری روم چگونه زندگی میکردند ؟ ... ...

H Douglas Brown Principles of Language.pdf ... ...

ابراهیم ویکتوری خدا دین علم بخش.mp3 ...

فیلم سوند گذاری در خانم ها.wmv ... ...
TahlilGaran TDictionary.apk ...
حج روزه زکات طهارت عقیده متفرقه نماز.pdf ...



عنوان پاورپوینت: دانلود پاورپوینت بازاریابی تجربی و استراتژی های آن فرمت: پاورپوینت قابل ویرایشتعداد اسلاید: 23پاورپوینت آماده ارائهفهرست مطالب:تعریف بازاریابی تجربی اهمیت بازاریابی تجربیدلایل اهمیت بازاریابی تجربی مزایای بازاریابی تجربی وظیفه بازاریابان تجربیمقایسه ... ...
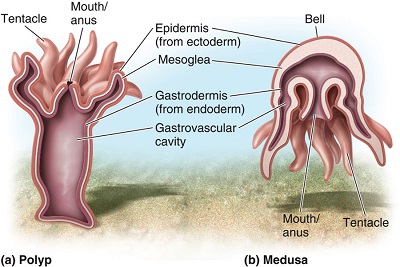
کیسهتنان نامی بود که در قدیم به شاخهای از بیمهرگان داده میشد. در طبقهبندیهای جدید بخش بزرگی از آن شاخه را جدا کرده و با نام مرجانیان میشناسند. حیواناتی از قبیل هیدر، مرجان، شقایق دریایی، و عروس دریایی در این گروه قرار داشتند. طول عمر این جانوران متفاوت است. مثال: ... ...

دانلود جزوه دستگاه غدد دانشگاه شهید بهشتی غده مجموعه ای از سلول هاست که موادشیمیایی تولید و ترشج کرده و بیرون می دهد. غده موادی را از خون انتخاب کرده و بیرون می کند، روی آنها فرایندهایی انجام می دهد و موادشیمیایی حال را برای استفاده در یک نقطه از بدن آزاد می کند. برخی ... ...

قدرت ذهن ناخودآگاه شما نوشته دکتر جوزف مورفی ترجمه رامین بختیاری کتاب صوتی قدرت ذهن ناخودآگاه شما از جمله کتاب های پرفروش سال است که در مقدمه مولف آمده است: با این کتاب زندگی خود را متحول کنید..من با چشم خود دیده ام که معجزه ها در همه جای دنیا و برای هر قشری از مردم ... ...

کتاب صوتی یک عاشقانه آرام نادر ابراهیمی از پرفروش ترین کتاب های سال با صدای #پیام_دهکردی ... ...
 پاورپوینت در مورد هخامنشیان
پاورپوینت در مورد هخامنشیان پروژه کارآموزی کارخانه قند شهرستان اقلید
پروژه کارآموزی کارخانه قند شهرستان اقلید پاورپوینت با موضوع اثرات استفاده از سیستم حمل و نقل دوچرخه در معابر شهری بر مصرف سوخت و ترافیک
پاورپوینت با موضوع اثرات استفاده از سیستم حمل و نقل دوچرخه در معابر شهری بر مصرف سوخت و ترافیک آساناهای یوگا به همراه تکنیک ها و توضیحات و تصاویر مربوط به هر وضعیت و حرکت
آساناهای یوگا به همراه تکنیک ها و توضیحات و تصاویر مربوط به هر وضعیت و حرکت پاورپوینت شناسایی الیاف (رشته طراحی دوخت)
پاورپوینت شناسایی الیاف (رشته طراحی دوخت) پاورپوینت خرده فروشی الکترونیکی در تجارت الکترونیک
پاورپوینت خرده فروشی الکترونیکی در تجارت الکترونیک پاورپوینت علم ورزش و تأثیر ورزش بر بیماریهای قلبی
پاورپوینت علم ورزش و تأثیر ورزش بر بیماریهای قلبی پاورپوینت سبک های فرزند پروری
پاورپوینت سبک های فرزند پروری پاورپوینت با موضوع اصول طراحی کارخانه
پاورپوینت با موضوع اصول طراحی کارخانه پاورپوینت با موضوع انواع تزئینات کاشی کاری
پاورپوینت با موضوع انواع تزئینات کاشی کاری متن آیت الکرسی به همراه ترجمه فارسی + PDFانواع معماری های مختلف پایگاه داده ها - Architectures
متن آیت الکرسی به همراه ترجمه فارسی + PDFانواع معماری های مختلف پایگاه داده ها - Architectures سها
سها لینک کارگزاری بانک های ایرانی جهت فروش و مدیریت سهام عدالت
لینک کارگزاری بانک های ایرانی جهت فروش و مدیریت سهام عدالت معاینات بدو استخدام و دوره ای شاغلین و هدف از انجام آن
معاینات بدو استخدام و دوره ای شاغلین و هدف از انجام آن خشکسالی و کم آبی و راه های مقابله با آن
خشکسالی و کم آبی و راه های مقابله با آن خلیج فارس
خلیج فارس انواع نظریه مدیریت
انواع نظریه مدیریت مبلغ وام دانشجویی ازدواج و تولد فرزند سال 1401 اعلام شد پاورپوینت خرده فروشی الکترونیکی در تجارت الکترونیک پاورپوینت در مورد هخامنشیان
مبلغ وام دانشجویی ازدواج و تولد فرزند سال 1401 اعلام شد پاورپوینت خرده فروشی الکترونیکی در تجارت الکترونیک پاورپوینت در مورد هخامنشیان پاورپوینت انواع ادوات FACTS - استتکام STATCOM پاورپوینت سبک های فرزند پروری پاورپوینت شناسایی الیاف (رشته طراحی دوخت) پروژه کارآموزی کارخانه قند شهرستان اقلید
پاورپوینت انواع ادوات FACTS - استتکام STATCOM پاورپوینت سبک های فرزند پروری پاورپوینت شناسایی الیاف (رشته طراحی دوخت) پروژه کارآموزی کارخانه قند شهرستان اقلید پاورپوینت خلاصه فصل 4 کتاب مبانی برنامه ریزی آموزشی
پاورپوینت خلاصه فصل 4 کتاب مبانی برنامه ریزی آموزشی پاورپوینت با موضوع بررسی مقررات مناطق آزاد و ویژه اقتصادی آساناهای یوگا به همراه تکنیک ها و توضیحات و تصاویر مربوط به هر وضعیت و حرکت
پاورپوینت با موضوع بررسی مقررات مناطق آزاد و ویژه اقتصادی آساناهای یوگا به همراه تکنیک ها و توضیحات و تصاویر مربوط به هر وضعیت و حرکت پاورپوینت توسعه پایدار و افزایش بهره برداری از منابع آب در بخش کشاورزی
پاورپوینت توسعه پایدار و افزایش بهره برداری از منابع آب در بخش کشاورزی پاورپوینت با موضوع اتحادیه کشورهای آسیای جنوب شرقی (آسه آن) Asean
پاورپوینت با موضوع اتحادیه کشورهای آسیای جنوب شرقی (آسه آن) Asean پاورپوینت با موضوع الکتروفورز Electrophoresis دانلود فایلهای بسته آمادهچاپ و نصب تابلو اعلانات مسجدنما هفته پنجم فروردین ماه 1403 پاورپوینت درس دهم قرآن هشتم سوره یس، سوره صافات و تفسیر نمونه حرکت تاریخی کرد به خراسان.pdf روانشناسی افسردگی.pdf سابلیمینال ایجاد رابطه و محبوب شدن پژوهی در پیدایش و تحولات تصوف و عرفان.pdf ژورنال مدل لباس عروس.pdf انقراض ششم.pdf تمدن اسلام و عرب.pdf کورد دوژمنی خۆت بناسە.pdf ما نمیمیریم.pdf تاریخ مصور جهان دنیای بستان.pdf H Douglas Brown Principles of Language.pdf دستنویس کتاب بوف کور.pdf فیلم سوند گذاری در خانم ها.wmv لسان الاعرب.pdf داستان راستان جلد2.pdf پاورپوینت بازاریابی تجربی و استراتژی های آن پاورپوینت کامل و جامع با عنوان دیرینه شناسی شاخه کیسه تنان در 43 اسلاید دانلود جزوه دستگاه غدد دانشگاه شهید بهشتی دانلود کتاب صوتی قدرت ذهن ناخودآگاه( از پرفروشترین کتابهای 1403) دانلود کتاب صوتی یک عاشقانه آرام نادر ابراهیمی(از پرفروش ترین کتاب های سال)
پاورپوینت با موضوع الکتروفورز Electrophoresis دانلود فایلهای بسته آمادهچاپ و نصب تابلو اعلانات مسجدنما هفته پنجم فروردین ماه 1403 پاورپوینت درس دهم قرآن هشتم سوره یس، سوره صافات و تفسیر نمونه حرکت تاریخی کرد به خراسان.pdf روانشناسی افسردگی.pdf سابلیمینال ایجاد رابطه و محبوب شدن پژوهی در پیدایش و تحولات تصوف و عرفان.pdf ژورنال مدل لباس عروس.pdf انقراض ششم.pdf تمدن اسلام و عرب.pdf کورد دوژمنی خۆت بناسە.pdf ما نمیمیریم.pdf تاریخ مصور جهان دنیای بستان.pdf H Douglas Brown Principles of Language.pdf دستنویس کتاب بوف کور.pdf فیلم سوند گذاری در خانم ها.wmv لسان الاعرب.pdf داستان راستان جلد2.pdf پاورپوینت بازاریابی تجربی و استراتژی های آن پاورپوینت کامل و جامع با عنوان دیرینه شناسی شاخه کیسه تنان در 43 اسلاید دانلود جزوه دستگاه غدد دانشگاه شهید بهشتی دانلود کتاب صوتی قدرت ذهن ناخودآگاه( از پرفروشترین کتابهای 1403) دانلود کتاب صوتی یک عاشقانه آرام نادر ابراهیمی(از پرفروش ترین کتاب های سال)استان فارس - کافی نت سها - 07144532022





